
 Download PDF
Download PDF This is an open access article distributed under the terms of the Creative Commons
Attribution License (
This is an open access article distributed under the terms of the Creative Commons
Attribution License (Увод [TOP]
Процедурата по проверка на статистическа значимостi e най-широко използвания метод за правене на статистически изводи в психологията. Въпреки популярността си обаче, процедурата e силно противоречива и често критикувана поради методологическите ѝ ограничения и неправилното ѝ използване от изследователите (Cohen, 1994; Gigerenzer, 2004; Johansson, 2011; Loftus, 1996; Lykken, 1968; Sanabria & Killeen, 2007; Wagenmakers, 2007; за преглед виж Lambdin, 2012 и Nickerson, 2000). В следствие на тези критики са предложени алтернативни методи за анализ на данни, които да служат като допълнение на традиционните тестове за проверка на статистическа значимост.
Настоящата статия разглежда няколко популярни погрешни схващания за тестовете на статистическа значимост и обсъжда защо резултатите от тях не ни дават достатъчно информация. След това се обсъждат допълнителни методи за анализ на данни, като дискусията се фокусира върху докладване на големина на ефекта и доверителни интервали. Големината на ефекта е количествено изразяване на величината и важността на даден феномен, а доверителните интервали показват несигурността ни за истинската стойност на даден параметър на популацията (Curran-Everett, 2009; Kelley & Preacher, 2012).
В емпиричната част се представят резултатите от преглед на статии публикувани в 3 български списания по психология с цел да се провери доколко тези допълнителни методи се докладват от авторите. Накрая се дават някои практически съвети и насоки за изчисляване на големина на ефекта и доверителни интервали, и се обсъждат начини, по които да се стимулира докладването им в изследователската литература.
Погрешни интерпретации на резултатите от тестове на статистическа значимост [TOP]
Поради широката разпространеност на тестовете на статистическа значимост, доскоро беше съвсем възможно някои изследователи да прекарат цялата си научна кариера без да са използвали друг метод за статистически изводи (Andrews & Baguley, 2013). Въпреки популярността им обаче, изненадващо e колко често резултатите от тестове на статистическа значимост се интерпретират погрешно. Анонимни проучвания, които представят на студенти и професори различни твърдения относно резултати от тестове на статистическа значимост, показват че почти всички анкетирани правят поне по една погрешна интерпретация на резултатите (Haller & Krauss, 2002; Oakes, 1986). Холър и Краус например откриват, че в извадката им 100% от студентите, 89% от академичните психолози и 80% от преподавателите по методология и статистика интерпретират погрешно поне едно от шест твърдения относно резултат от тест на значимост. Погрешното интерпретиране на резултатите обаче не е характерно само за психолозите и дори опитни статистици не са имунизирани срещу него, особено при липсата на статистическа значимост (Lecoutre, Poitevineau, & Lecoutre, 2003).
Една от честите причини за погрешни интерпретации е свързана с тълкуването на p стойностите, които се получават от тестовете на статистическа значимост. Това, което p стойностите действително показват, е теоретичната вероятност, че ако две нeзависими извадки със същия размер са избрани случайно от същата популация, статистическият тест ще получи стойност толкова голяма, или по-голяма, от наблюдаваната (Nickerson, 2000). С други думи, ако едно изследване например проверява дали експерименталната група има по-бързо време на реакция от контролната група, p стойността ще покаже каква е вероятността, ако се изтегли втора случайна извадка със същия размер от същата популация, че ще се получи стойност на статистическия тест (напр. Т test), която е също толкова голяма, или по-голяма, от наблюдаваната.
P стойностите обаче често се интерпретират по различни погрешни начини: 1) като вероятността за грешка ако нулевата хипотеза е отхвърлена; 2) вероятността, че нулевата хипотеза е вярна с оглед на данните; 3) вероятността, че резултатът ще бъде репликиран при същите условия; 4) или че p стойностите показват големината на ефекта (т.е, по-ниски p стойности показват по-голям ефект; Kline, 2004). Всяка от тези интерпретации се основава на различни погрешни вярвания и интересуващите се читатели могат да ги прочетат в Kline (2004, стр. 63-68). За целите на дискусията ще бъде разгледано единствено четвъртото вярване- че p стойностите показват големината на ефекта. Тестовете на значимост са критикувани и на други основания, освен погрешната интерпретация, но те няма да бъдат разглеждани тук, защото не са централни за настоящата дискусия (напр. виж Cohen, 1994).
Допълнителни методи за анализ на резултати от тестове на статистическа значимост [TOP]
Големина на ефекта — Нека да се върнем към примера за изследването с време на реакция. Ако един експериментатор проведе такова изследване и след сравняване на средните стойности на експерименталната и контролната група получи определена p стойност, защо сама по себе си тя не може да се използва за оценка на големината на ефекта? Причината е, че тестовете на статистическа значимост и съответстващите им p стойности зависят както от големината на извадката, така и от големината на ефекта. По този начин, пренебрежително малък ефект може да стане статистически значим, ако извадката е достатъчно голяма (Kline, 2004). Тази зависимост от големината на извадката е и причината защо p стойностите не могат да се използват сами по себе си за оценка на големината на ефекта. Тестът може да покаже, че няма статистически значими разлики между средните стойности на експерименталната и контролната група, но това не означава, че силата на ефекта също е незначителна- възможно е просто изследването да няма достатъчна статистическа мощност, която да разкрие ефект, когато има такъв (виж Maxwell, 2004).
За да се преодолее този проблем е необходимо докладването на големина на ефекта (American Psychological Association [APA], 2009; Chow, 1988; Hedges, 2008; Kelley & Preacher, 2012; Volker, 2006; Wilkinson & Task Force on Statistical Inference, 1999). Големината на ефекта описва размерa на наблюдавания ефект и е подходящa за определянето на практичната и теоретичната му стойност. Изследвания със същите описателни характеристики (като средна стойност и стандартно отклонение) ще имат еднаква големина на ефекта, без значение от размера на извадката и дали получените различия са статистически значими. Поради тази причина и докладваната големина на ефекта може да бъде използвана в бъдещи мета-анализи и при определяне на статистическата мощност на последващи изследвания (Fritz, Scherndl, & Kühberger, 2013; Volker, 2006).
Ползата от докладването на големина на ефекта е съществена, защото по този начин е възможно да се определи каква е практическата значимост на резултатите. Получената статистическа значимост от даден тест не ни казва много извън това каква е вероятността резултатите да се дължат на случайна флуктуация в извадката. Практическата значимост, от друга страна, се отнася до това дали резултатът е полезен в истинския свят (Kirk, 1996). Поради тази причина, статистическата значимост не трябва да се бърка с практическата значимост.
Въпреки това обаче, в литературата лесно могат да се намерят много примери за статии, в които авторите дискутират значимостта на резултатите си единствено чрез получените p стойности. Статистическата значимост не винаги предполага и практическа значимост, но психолозите често интерпретират статистически значими резултати в дискусията като важни, големи и много значими (Cohen, 1994). Това е един парадокс, защото p стойностите сами по себе си не ни казват това, което наистина искаме да знаем- каква е големината на наблюдавания ефект и каква е неговата практическа стойност? Поради тази причина е необходимо големината на ефекта да се докладва заедно с получената статистическа значимост.
Доверителни интервали — Друг проблем, свързан с процедурата за проверка на статистическа значимост, е че тя е ориентирана към правене на дихотомни решения- нулевата хипотеза или се отхвърля или не се отхвърля (Fidler & Cumming, 2007). В следствие на това, изследователите формулират теории по отношение на това дали дадени променливи имат ефект върху други променливи. В най-добрия случай може да има предсказване на посоката, но не и точкова оценка на параметъра на популацията или прецизността на тази оценка (Cumming & Fidler, 2009).
Поради тази причина се препоръчва и докладването на доверителни интервали (APA, 2009; Cumming & Fidler, 2009; Thompson, 2002). Доверителните интервали са полезни, защото показват несигурността, която имаме при оценяване на истинската стойност на популацията по даден параметър. Например, ако изчислим доверителни интервали за средна стойност на дадена популация, можем да очакваме с определено ниво на сигурност (обикновено 95% или 99%), че истинската стойност на популацията ще попадне в този интервал. По този начин, доверителните интервали показват същата статистическа информация като p стойностите, но избягват някои от недостатъците на тестовете на значимост (Curran-Everett, 2009).
Доверителните интервали са полезни за оценка на несигурността при определяне на средната стойност на популацията и могат да бъдат представени графично като отсечки на грешката. Препоръчително е обаче доверителни интервали да се изчисляват и за докладваната големина на ефекта (Fritz, Morris, & Richler, 2012; Kelley, 2007а; Kelley & Preacher, 2012).
Отсечки на грешката — Отсечките на грешката се използват при графично изобразяване на данни и най-често могат да показват доверителни интервали, стандартна грешка или стандартно отклонение. Тук ще бъдат дискутирани само отсечки на грешката, изобразяващи доверителни интервали, защото те имат най-голямо отношение към проблемите дискутирани в тази статия.
Визуалното представяне на доверителни интервали на средни стойности може да се използва за бърза и лесна оценка на степента, до която получените средни стойности от извадката могат да се вземат „на сериозно” за определяне на средните стойности на популацията (Fidler & Loftus, 2009). Голямо предимство на отсечките на грешката е, че дължината им дава визуална представа за това колко несигурност има в данните ни- по-дългите отсечки показват голяма грешка, а по-малките показват малка грешка (Cumming, Fidler, & Vaux, 2007). За да бъдат информативни обаче, отсечките на грешката сами по себе си не са достатъчни, а е необходимо в легендата да бъде обяснено и за какво се отнасят те.
Настоящо изследване — Докладването на големина на ефекта и доверителни интервали е не само препоръчително, но и необходимо, за да се избегнат някои от проблемите свързани с тестовете на статистическа значимост. Въпреки че докладването им през последното десетилетие се е увеличило, тази промяна е сравнително бавна (Cumming, Fidler, Leonard, et al., 2007). Предишните опити да се определи колко често големината на ефекта и доверителни интервали се докладват в емпирични статии обаче са извършени с анализ на англоезични списания. Поради тази причина, настоящото проучване цели да провери доколко те се докладват в български списания по психология.
Методология [TOP]
Данни [TOP]
Данните бяха събрани чрез преглед на три български списания по психология: Психологични Изследвания, Психологическа Мисъл и Българско Списание по Психология (Balgarsko Spisanie po Psihologiâ [http://bjop.wordpress.com]; Psihologični Izsledvaniâ [http://spi.free.bg]; Psychological Thought [http://psyct.psychopen.eu]). Събрани бяха всички емпирични статии публикувани между 2007 и 2012г. От списание „Психологическа Мисъл” липсваха статии публикувани между втората половина на 2009 и 2012г. поради временно прекъсване на издаването на списанието. Също така, по време на събирането и обработка на данните (Юли 2013г.), втори брой на списание „Психологични Изследвания” все още беше под печат.
През разглеждания период в „Българско Списание по Психология” са публикувани и доклади от два национални конгреса и една международна конференция. Понеже докладите не са реферирани както останалите статии, резултатите ще бъдат представени по два начина: първо, отделно за реферираните статии и след това за докладите и реферираните статии взети заедно. И трите списания са публикували емпирични статии както на български, така и на английски език.
Кодиране [TOP]
Всички емпирични статии и доклади (N = 455) бяха прегледани и кодирани за това дали използват тестове за проверка на статистическа значимост. От тях, 74.94% използваха един или повече такъв тест; от останалите статии, най-често използвани бяха описателната статистика (11.86%) и качествените методи (5.71%). От статиите, използващи тестове за проверка на статистическа значимост, бяха премахнати тези, които използват единствено корелационни или регресионни анализи (или комбинация от двете). Причината за това е, че r и R2 стойностите, които се използват за оценка на големината на ефекта, стандартно се докладват при описване на резултатите и се извеждат от повечето стандартни софтуерни пакети (пр. SPSS). При логистичната регресия, големината на ефекта се оценява чрез т.н. съотношение на шансовете (Field, 2009). Три доклада и една статия бяха изключени поради неясно докладване на резултатите.
Останалите 253 статии и доклади бяха кодирани и използвани в последващите анализи. Таблица 1 показва броя реферирани статии, кодирани през шестте години за трите списания. Таблица 2 показва броя доклади, кодирани за двата конгреса и конференцията.
Всички статии и доклади бяха кодирани според това дали докладват: 1) доверителни интервали, 2) големина на ефекта, 3) доверителни интервали на големината на ефекта, и 4) отсечки на грешката при графики. Отсечки на грешката бяха кодирани когато авторите докладват средни стойности в графичен вид, но не и когато представят описателна статистика под формата на графики. Статиите и докладите също бяха кодирани за това дали са написани на български (69.6%) или на английски език (30.4%). Повечето от тези на английски език (75.3%) са от международната конференция през 2009г.
Резултати [TOP]
Сравнителните анализи на данните ще бъдат представени предимно в проценти. Понеже броят на статиите в извадката е малък, не беше възможно да се направят по-фокусирани сравнения, без да се нарушат допусканията на статистическите тестове.
Големина на ефекта [TOP]
От всички кодирани статии, едва 13.43% докладват големина на ефекта за поне един статистически тест. Подобен резултат се получи и за всички реферирани статии (13.04%), и за всички доклади (13.66%), като разликата между двата типа публикации не е статистически значима, χ2 (1) = .019, p = .889, φ = .009. Коефицентът φ показва ефект с пренебрежимо малка големина. Фигура 1 представя разпределението по години на статии, докладващи големина на ефекта. При докладите, 5.66% от тях докладват големина на ефекта от конгреса през 2008г., а 8% докладват големина на ефекта от конгреса през 2011г. Процентът за конференцията през 2009г. е 25.86.
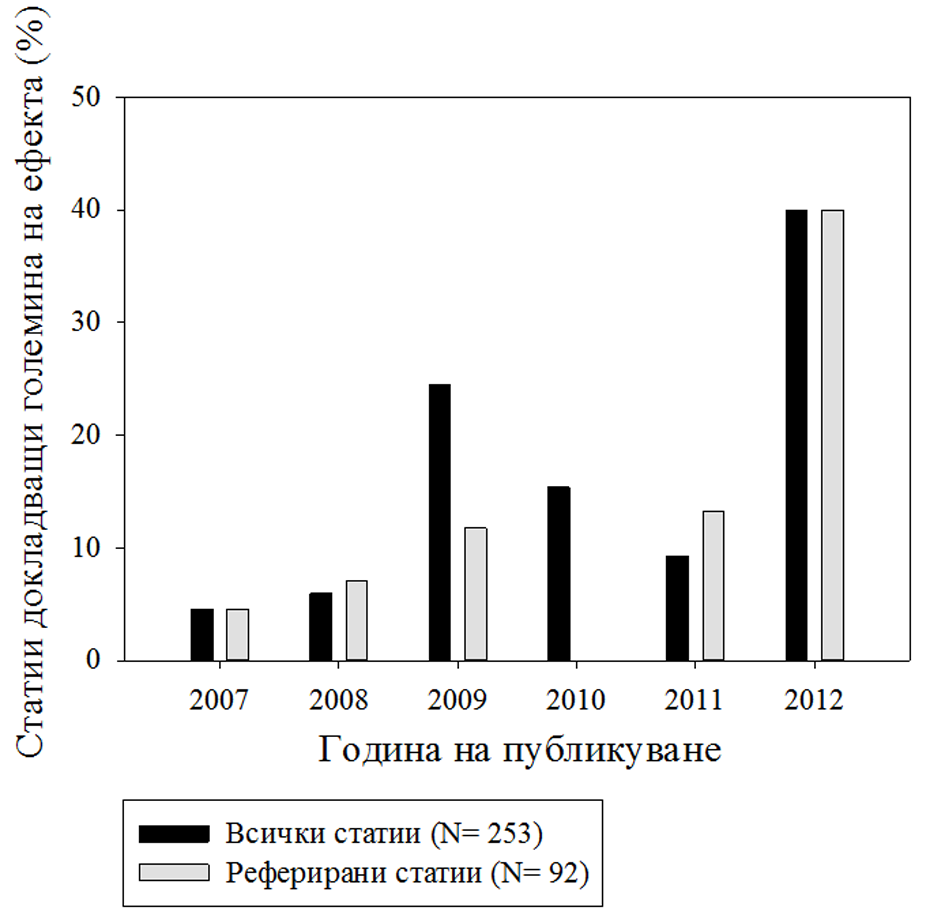
Резултатите показват, че има увеличение в процента статии, докладващи големина на ефекта през годините, като той е най-висок през 2012г. Въпреки че скокът от 2011 до 2012г. изглежда висок, възможно е той отчасти да се дължи на малкия брой кодирани (и публикувани) статии през 2012г- едва 5.92% от всички статии и доклади.
При сравнение на статиите по език на публикация, 7.38% от всички статии и доклади на български език и 27.27% на английски език докладват големина на ефекта за поне един анализ. По този начин, публикациите на английски език по-често докладват големина на ефекта от тези на български език, като разликата е статистически значима, χ2 (1) = 18.210, p < .001, φ = .268. Коефицентът φ показва ефект с малка големина. При анализ на статиите, докладващи големина на ефекта, 55.88% от тях докладват големина на ефекта за всички проведени анализи. Също така, при повторен преглед на всички статии, докладващи големина на ефекта, едва 35.2% правят поне някакъв опит да го интерпретират в текста на статията.
Доверителни интервали [TOP]
От всички статии и доклади, едва 3.57% докладват доверителни интервали за средните стойности. Фигура 2 представя разпределението по години. Също така, в нито една от статиите, докладващи големина на ефекта, не бяха изчислени доверителни интервали за него.
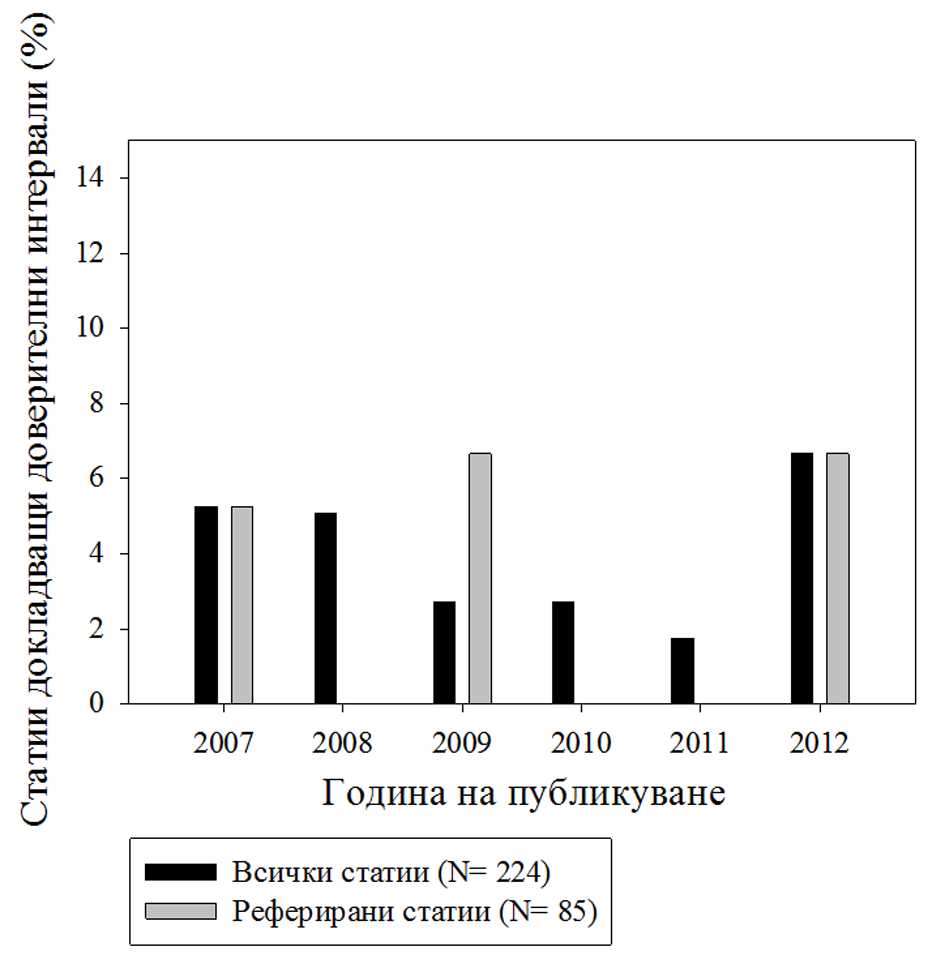
На конгреса през 2008г., 6% от статиите докладват доверителни интервали за средните стойности, а на конгреса в 2011г.- 5.66%. На конференцията през 2009г процентът е 1.72
Отсечки на грешката [TOP]
От всички статии и доклади, изобразяващи средни стойности чрез графики (N = 64), едва 12.5% имат отсечки на грешката. Разпределението по години е показано на Фигура 3.
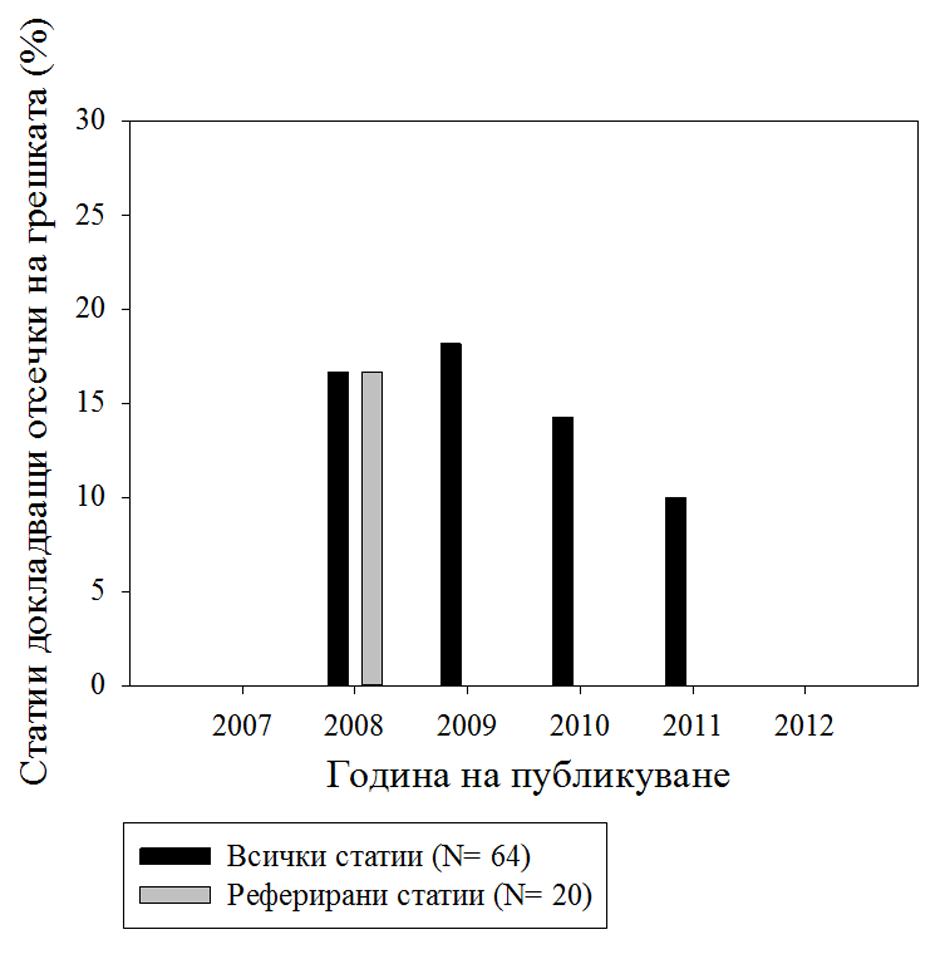
От осемте статии, докладващи отсечки на грешката обаче, само 5 споменават експлицитно какво отразяват отсечките (три статии показват доверителни интервали, една показва стандартна грешка и една показва стандартно отклонение).
Дискусия [TOP]
Целта на настоящото проучване беше да провери степента, до която авторите на статии в български списания докладват големина на ефекта и доверителни интервали. Резултатите показват, че за шестте години малко публикувани статии докладват големина на ефекта. Въпреки че процентът се увеличава с годините, все още по-малко от половината статии през 2012г. докладват големина на ефекта.
През 2012г. се наблюдава по-голямо увеличение на статиите, докладващи големина на ефекта, в сравнение с предходните години. Възможно е това да отразява промяна в желаната посока. От друга страна обаче, възможно е и процентите за някои години да са изкуствено завишени или занижени поради малкото кодирани статии. Поради тази причина, разпределението по години трябва да се разглежда по-скоро като приблизително.
Проверката за статии, докладващи доверителни интервали, показва, че те почти не се докладват; също така, процентът на статии, докладващи доверителни интервали, варира през годините и не се открива някаква ясна времева тенденция. Подобен резултат се получи и за статиите, изобразяващи отсечки на грешката, въпреки че процентът е малко по-висок от статиите докладващи доверителни интервали. Като цяло не се наблюдават разлики между публикуваните реферирани статии и доклади. Това подсказва, че редакторските колективи и рецензентите на списанията през тези години вероятно не са оказали забележимо въздействие върху докладването на големина на ефекта и доверителни интервали.
Tези резултати се различават от други проучвания на статии, публикувани в англоезични списания, които откриват, че средно 38.4% от статиите докладват големина на ефекта и 10.4% докладват доверителни интервали (Fritz, Scherndl, & Kühberger, 2013). Това предполага, че статиите, публикувани в български списания, по-рядко докладват големина на ефекта и доверителни интервали в сравнение с англоезичните списания. Това заключение се подкрепя и от анализа на статии публикувани на български и английски език- тези публикувани на английски език докладват по-често големина на ефекта.
Въпреки че докладването на големина на ефекта е важно, в повечето случаи е необходимо и той да се интепретира при дискутирането на резултатите (Kelley & Preacher, 2012). Едва около една трета от статиите с големина на ефекта обаче правят това в настоящата извадка. Затова, освен самото докладване на големината на ефекта, важно е да бъде обсъдено и какво означава той в контекста на изследването. Също така, препоръчително е и да се изчисляват доверителни интервали за големината на ефекта (Kelley, 2007a). В настоящото проучване обаче, в нито една статия, докладваща големина на ефекта, не бяха изчислени и доверителни интервали за него.
В остатъка от статията ще бъдат обсъдени накратко някои по-често използвани индекси за големина на ефекта и начини за изчислението им. Ще се обсъдят и начини за изчисляване на доверителни интервали. Целта не е да се направи изчерпателен обзор на литературата, а по-скоро да се изведе на едно място най-съществената информация за изчисляване на големина на ефекта и доверителни интервали. За по-подробен обзор, читателите могат да се обърнат към Kline (2004) и Grissom и Kim (2005).
Индекси за големина на ефекта: видове и изчисляване [TOP]
Индексите за големина на ефекта могат да се разделят най-общо на две групи или „семейства”: разлики между групи (d семейство) и мерки на асоциация (r семейство; Ellis, 2010). В тази секция ще бъдат представени някои по-често използвани индекси и начини за тяхното изчисление.
Разликa между групи (d семейство) — Индексите от d семейството са подходящи за експериментални дизайни, където има сравнение на две групи и където зависимата променлива е непрекъсната, а независимата е категориална (Nakagawa & Cuthill, 2007). Трите най-често използвани индекси от тази група са представени в Таблица 3. Индексите се различават единствено по знаменателя си, понеже има повече от един начин, по който може да се определи стандартното отклонение на полулацията (Kline, 2004). Делта на Глас (Δ) използва единствено стандартното отклонение на контролната група и поради тази причина е по-подходящ, ако се смята, че експерименталната манипулация е изкривила разпределението по някакъв начин (Fritz, Morris, & Richler, 2012).
Таблица 3
Индекси за големина на ефекта при параметрични тестове (d семейство)
| Статистически тест | Индекс | Формула | Пояснение | Източници |
|---|---|---|---|---|
| T тест | d на Коен (Cohen’s d) |  |
M1 - M2 е разликата в двете средни стойности;  |
(Cohen, 1988) |
| T тест | Делта на Глас (Δ) (Glass’ delta) |  |
Me - Mc е разликата в средните стойности на експерименталната и контролната група; SDc е стандартното отклонение на контролната група | (Grissom & Kim, 2005) |
| T тест | g на Хеджис (Hedges’ g) |  |
 |
(Grissom & Kim, 2005) |
D на Коен и g на Хеджис, от друга страна, изчисляват големина на ефекта чрез обединяване на стандартното отклонение на двете групи. G на Хеджис представлява модификация на d на Коен, и въпреки че не е много добър предиктор на стандартното отклонение на популацията, той представлява по-стандартизирана мярка от другите два индекса в тази група (Ferguson, 2009). В някои случаи обаче, d на Коен и g на Хеджис имат склонност да надценяват съответния параметър: колкото по-малка е извадката и колкото по-голям е ефектът на популацията, толква повече се увеличава позитивното изкривяване (Grissom & Kim, 2005). G на Хеджис e по-малко склонен към това изкривяване в сравнение с d на Коен. Също така, според Клайн (Kline, 2004), g на Хеджис като цяло е по-полезният от двата индекса.
Измерване на сила на взаимовръзката (r семейство) — Най-често използваните индекси в това семейство са представени в Таблица 4. Посочените индекси могат да се използват както за корелационни, така и за експериментални дизайни (Snyder & Lawson, 1993).
Таблица 4
Индекси за големина на ефекта при параметрични тестове (r семейство)
| Статистически тест | Индекс | Формула | Пояснение | Източници |
|---|---|---|---|---|
| Дисперсионен анализ (еднофакторен / двуфакторен) | Ета на квадрат ( ) )(Eta squared) |
 |
SSBetween e сбор на квадратите между групите; SSTotal e цялостен сбор на квадратите | (Shaughnessy, Zechmeister, & Zechmeister, 2012) |
| Дисперсионен анализ (еднофакторен / двуфакторен) | Частична Ета на квадрат ( ) )(Partial eta squared) |
 |
SSError e грешката на сумата на квадратите | (Levine & Hullett, 2002) |
| Дисперсионен анализ (еднофакторен) | Епсилон на квадрат ( ) (Epsilon squared) ) (Epsilon squared)
|
 |
df e степените на свобода; MSError e среден квадрат на грешката; SS е сбор на квадратите | (Snyder & Lawson, 1993) |
| Дисперсионен анализ (еднофакторен / двуфакторен) | Омега на квадрат ( ) (Omega squared) ) (Omega squared)
|
 |
(Snyder & Lawson, 1993) | |
| Дисперсионен анализ (еднофакторен / двуфакторен) | Частична Омега на квадрат ( ) (Partial omega squared) ) (Partial omega squared)
|
 |
(Olejnik & Algina, 2003) | |
| Дисперсионен анализ (еднофакторен) | ƒ на Коен (Cohen’s ƒ) |  |
η2 е Ета на квадрат | (Cohen, 1988) |
| Множествена регресия/ Йерархична множествена регресия* |
ƒ2 на Коен (Cohen’s ƒ2) |   |
R2 e коефициентът на детерминация; RB e променливата от интерес, а RA е групата от всички останали променливи | (Selya, Rose, Dierker, Hedeker, & Mermelstein, 2012) |
Бележка: „Шапката” ( ) над гръцките букви означава, че индексът се отнася за извадката; индексите без нея
се отнасят до параметъра на популацията (Kline, 2004). В статията се обсъжда големина на ефекта за извадката, но той също така може да
бъде изчислен и за популацията.
) над гръцките букви означава, че индексът се отнася за извадката; индексите без нея
се отнасят до параметъра на популацията (Kline, 2004). В статията се обсъжда големина на ефекта за извадката, но той също така може да
бъде изчислен и за популацията.
Ета на квадрат ( ) е един традиционен индекс за измерване на силата на асоциация, който обаче има известни
проблеми понеже проявява позитивно изкривяване и е склонен да надценява ефекта на
популацията (Grissom & Kim, 2005). Един вариант на този индекс е частичната Ета на квадрат (
) е един традиционен индекс за измерване на силата на асоциация, който обаче има известни
проблеми понеже проявява позитивно изкривяване и е склонен да надценява ефекта на
популацията (Grissom & Kim, 2005). Един вариант на този индекс е частичната Ета на квадрат ( ), която се изчислява от SPSS. В по-старите версии на програмата индексът е докладван
като , но това сега е поправено (Levine & Hullett, 2002). Сравнително честа практика при двуфакторен дисперсионен анализ e да се докладва
за цялостния ефект и за индивидуалните ефекти (Kline, 2004).
), която се изчислява от SPSS. В по-старите версии на програмата индексът е докладван
като , но това сега е поправено (Levine & Hullett, 2002). Сравнително честа практика при двуфакторен дисперсионен анализ e да се докладва
за цялостния ефект и за индивидуалните ефекти (Kline, 2004).
Епсилон на квадрат ( ) e друг индекс подобен на , който като цяло се смята, че показва по-малко изкривяване при определяне на големината
на ефекта (Grissom & Kim, 2005). Омега на квадрат (
) e друг индекс подобен на , който като цяло се смята, че показва по-малко изкривяване при определяне на големината
на ефекта (Grissom & Kim, 2005). Омега на квадрат ( ) също има по-малко изкривяване при определяне на обяснената вариация на популацията
в сравнение с . Двата индекса започват да клонят към една и съща стойност с увеличаването на размера
на извадката и затова е за предпочитане при по-малки извадки (Kline, 2004). Характерно за също е, че определя големината на ефекта на популацията, вместо този на самото изследване
(Fritz, Morris, & Richler, 2012). Един вариант на е частичната Омега на квадрат (
) също има по-малко изкривяване при определяне на обяснената вариация на популацията
в сравнение с . Двата индекса започват да клонят към една и съща стойност с увеличаването на размера
на извадката и затова е за предпочитане при по-малки извадки (Kline, 2004). Характерно за също е, че определя големината на ефекта на популацията, вместо този на самото изследване
(Fritz, Morris, & Richler, 2012). Един вариант на е частичната Омега на квадрат ( ). Разликата му се състои в това, че измерва силата на ефекта като отношение на вариацията,
която не може да бъде преписана на други ефекти (Grissom & Kim, 2005). Както получава по-малко изкривени резултати в сравнение с , така и реултатите на са по-малко изкривени в сравнение с .
). Разликата му се състои в това, че измерва силата на ефекта като отношение на вариацията,
която не може да бъде преписана на други ефекти (Grissom & Kim, 2005). Както получава по-малко изкривени резултати в сравнение с , така и реултатите на са по-малко изкривени в сравнение с .
ƒ2 на Коен е подходящ за изчисляване на големината на ефекта при множествена регресия,
когато независимата и зависимата променлива са непрекъснати. Този индекс може да се
използва и при йерархична множествена регресия. ƒ2 на Коен може да се изчисли и със статистическата програма SAS (виж Selya et al., 2012). Вариация на този индекс, ƒ на Коен, може да се използва и за еднофакторен дисперсионен
анализ. Както се вижда на Таблица 4, ƒ на Коен може да се изведе лесно след като е изчислен .
Непараметрични тестове и анализ на други типове данни — Докладването на големина на ефекта за непараметрични тестове понякога се пренебрегва, но то е също толкова важно, колкото и за параметрични тестове. За тестовете на Ман Уитни и Уилкоксън, големината на ефекта може да се изчисли с помощта на z стойността, която се извежда от статистически пакети като SPSS (Fritz, Morris, & Richler, 2012; виж Таблица 5).
Таблица 5
Индекси за големина на ефекта при непараметрични и други видове тестове
| Статистически тест | Индекс | Формула | Пояснение | Източници |
|---|---|---|---|---|
| Тест на Ман Уитни/ Уилкоксън (Mann-Whitney/Wilcoxon test) | r |  |
z e стойността от теста; N e броят наблюдения | (Fritz, Morris, & Richler, 2012) |
| χ2 тест | ϕ коефици-ент |  |
χ2 е стойността от теста; N e броят наблюдения | (Chedzoy, 2006) |
| χ2 тест (>2x2 таблица) | V на Крамéр (Cramér's V) |  |
k e броят редове или колони (по-малката от двете стойности) | (Cramér, 1946) |
| N/A | Съотношение на шансовете (Odds Ratios) |  |
А = [+ излагане, + изход]; B = [+ излагане, - изход]; C = [- излагане, + изход]; D = [- излагане, - изход] |
(Szumilas, 2010) |
При категориални данни анализирани с χ2 тест, големината на ефекта може да се изчисли с няколко индекса. Коефицентът ϕ е подходящ когато данните се анализират като 2x2 таблица. Когато таблицата е по-голяма (т.е. има повече от две колони или редици), по-подходящо е да се използва модифицирания индекс V на Крамéр. Трети индекс, ламбда на Гудман и Крускълс (λ) (Goodman and Kruskal's lambda), пък се използва когато има предсказване на резултат при категориални променливи. Той измерва пропорционалното увеличаване на правилното предсказване на изхода за една категориална променлива, когато имаме информация за втора категориална променлива. Например, бихме могли да проверим доколко способността ни да предскажем дали студентите ще си вземат или няма да си вземат изпита се определя от това, че знаем пола им (Cramer & Howitt, 2004). И трите индекса за големина на ефекта могат да бъдат изчислени от SPSS, ако са избрани като опция.
Друг индекс на големина на ефекта е т.н. съотношение на шансовете. То като цяло има по-широко приложение в медицината, но е приложимо и в психологията при биномиални данни. Съотношението на шансовете се използва за сравнение на относителната вероятност на изхода, от който се интересуваме (например болест или разстройство), при излагане на променливата от интерес (за повече информация виж Szumilas, 2010).
Калкулатори за големина на ефекта [TOP]
Въпреки че не всички индекси могат да се изчисляват от повечето статистически пакети, съществуват някои онлайн калкулатори, които могат да спестят ръчното смятане по формулите. С калкулаторът на Wilson (n.d.) могат да се изчислят голям брой индекси, включително и повечето обсъждани тук. Други полезни калкулатори са на Ellis (2009) и Lyons и Morris (2013).
Докладване на големина на ефекта [TOP]
Според насоките на Американската Психологическа Асоциация, „почти винаги [e] необходимо да се включи някаква мярка на големината на ефекта при резултатите” (APA, 2009, стр. 34). Както беше описано досега, съществуват различни индекси, по които може да се изчисли големината на ефекта, а при някои дизайни има избор между повече от един индекс.
Тъй като различните индекси се изчисляват по различен начин, получените стойности не винаги са еквиваленти и могат да се тълкуват по един и същ начин. Поради тази причина, важно е при докладването на големина на ефекта да се спомене чрез кой точно индекс е изчислен (Ellis, 2010). Индексите от d семейството могат да се преобразуват в индекси на силата на асоциация (и обратно) по следните формули (Ferguson, 2009):


Cohen (1988) въвежда няколко критерия за оценка на ефектите като „малки”, „средни” и „големи” (виж също Cohen, 1992; Ellis, 2010, cтр. 40-42). Например, за d на Коен, стойност от .20 показва малък ефект, .50 показва умерен ефект и .80 показва голям ефект. Тези критерии са полезни, защото водят до по-лесно сравняване на големината на ефекта в различни изследвания. Въпреки това, според някои изследователи критериите са противоречиви и като цяло е препоръчително големината на ефекта да се интерпретира в контекста на изследователската област (Ellis, 2010; Zakzanis, 2001).
Изчисляване на доверителни интервали [TOP]
Доверителните интервали за средни стойности могат да бъдат изведени лесно със стандартните статистически пакети и затова изчисляването им няма да бъде дискутирано тук (формули могат да бъдат намерени в Cumming & Fidler, 2009). Изчисляването на доверителните интервали за големина на ефекта обаче не е същото като доверителните интервали за параметри като средна стойност и стандартно отклонение (Thompson, 2002). Като цяло, тези доверителни интервали се изчисляват по-трудно, защото зависят от нецентралните t, F и χ2 разпределения (Kelley, 2007a). Cumming (2012) предлага Excel макроси (като допълнение към книгата си), с които могат да се изчисляват доверителни интервали на d и r индекси. Самите макроси са със свободен достъп и могат да се използват и без книгата (виж Cumming, n.d.). Kelley (2007a) пък описва скриптове за изчисляване на доверителни интервали за големина на ефекта с помощта на MBESS- пакет за програмата R (виж Kelley, 2007b). Също така, калкулаторът на Wilson (n.d.) изчислява 95% доверителни интервали за индексите.
Стимулиране на докладването на големина на ефекта и доверителни интервали [TOP]
Промяната в начина на анализиране на данните е необходима, за да се избегнат някои от недостатъците на тестовете за проверка на статистическа значимост (Loftus, 1996). Както обаче се вижда от представените данни, все още сравнително малко изследователи в България докладват големина на ефекта, а още по-малко докладват доверителни интервали. Съществуват поне два начина, по-които може да се стимулира докладването им от изследователите.
Първо, създаването на редакторски указания от реферираните списания в България ще доведе до увеличаване на процента автори, докладващи големина на ефекта и доверителни интервали. Тези указания биха могли да се разширят и до рецензентите, които също да следят за докладването им. Въпреки че е възможно някои автори отново да не ги интерпретират в дискусията си (Fidler, Thomason, Cumming, Finch, & Leeman, 2004), това все пак е положителна стъпка напред.
Подобна инициатива би била още по-ефективна, ако е подкрепена и от професионалните сдружения на психолозите в България. Положителен пример в тази насока е Американската Психологическа Асоциация, която изисква докладването на големина на ефекта и доверителни интервали в списанията, публикувани от асоциацията (виж APA, 2009, стр. 33).
Друга по-обещаваща стратегия е тези допълнителни методи за анализ на данни да се преподават рутинно по време на обучението на студентите по Статистика (Schmidt, 1996). Самите студенти не са привикнали да използват механично тестовете за проверка на статистическа значимост и затова биха били по-пластични при усвояването на тези алтернативни методи (Kline, 2004). В последните няколко години са публикувани подходящи книги, които въвеждат в проблема (напр. Cumming, 2012; Ellis, 2010) и които биха могли да се изпoлзват за обучение. Публикувани са и статии, написани на по-разбираем език, които също могат да се използват за тази цел (напр. Cohen, 1990; Cumming & Fidler, 2009; Cumming & Finch, 2005; Hedges, 2008).
Заключение [TOP]
Въпреки широкото си разпространение, процедурата за проверка на статистическа значимост не е без своите недостатъци и резултатите от нея често са интерпретирани погрешно. За да се избегнат някои от тези проблеми, е необходимо да се използват допълнителни методи за анализ на данни, като изчисляване на големина на ефекта и доверителни интервали. Подобно на предишни проучвания в англоезичната литература, анализът на публикувани статии в три български списания по психология показа, че тези два метода се докладват рядко и почти не се обсъждат в дискусията. Промяната към докладването им е не само желателна, но и необходима стъпка, защото така ще се подобрят значително сегашните практики за анализ и интерпретация на данни, и присъщите им недостатъци.
