
 Download PDF
Download PDF This is an open access article distributed under the terms of the Creative Commons
Attribution License (
This is an open access article distributed under the terms of the Creative Commons
Attribution License (Introduction [TOP]
Human communication depends on voice/non-voice and speech/non-speech sounds associated with cortically-specific areas in the brain (Binder, Frost, Hammeke, Bellgowan, et al., 2000). Through voice, humans can analyse information about an individual’s sex, age, emotions, even if one’s language is not familiar to the language the person is listening to (Ward, 2010). Human voice is a powerful tool for speech processing in terms of identification of voice-specific vs. non-voice specific sounds. Human voice is activated via brain regions which are voice-selective and can be found in the auditory cortex (Belin, Fecteau, & Bédard, 2004; Belin, Zatorre, & Ahad, 2002; Belin, Zatorre, Lafaille, Ahad, & Pike, 2000). Recognition of an individual is also a voice-related characteristic, though one’s identity is more easily accessed by looking at one’s face, instead of listening to one’s voice (Hanley, Smith, & Hadfield, 1998).
Voice-selective areas are auditory cortical regions triggered not only by human sounds, but by socially-related information, linked to other sensory systems as well, such as vision, touch and proprioception (Tsao, Freiwald, Tootell, & Livingstone, 2006). Voice-selective areas are located in the superior temporal lobes of the auditory cortex – function of the ‘what’ sourcei –, and are activatedii during the operation of human vocal sounds (Vuilleumier, 2005) where responsiveness to vocal sounds exhibits greater neural sensitivity (Belin et al., 2000)iii. By voice-selectivity it is meant that the brain reacts more accurately in the hearing of human sounds compared to non-human ones (Belin et al., 2000).
Human voice differs from non-human in that it refers to vocalised speech (Levy, Granot, & Bentin, 2001). Superior temporal regions respond to voice-selectivity in regard to vocalised-specific information as well as affective communicationiv (Ethofer, Anders, Erb, et al., 2006; Ethofer, Anders, Wiethoff, et al., 2006). Voice-selective areas are found in the same sensory tracts both in humans and primates (Petkov et al., 2008).
Voice-selective areas are activated in voice-selective regions sensitive to the increase and/or decrease of human vocal sounds when modulated by attention-related factors, such as spatial and selective attention to tasks (Hashimoto, Homae, Nakajima, Miyashita, & Sakai, 2000). That means superior temporal lobes react to human sounds by demonstrating higher receptivity compared to non-human ones. Vocal-sound areas can be speech and/or non-speech, for the neural activity they exhibit is higher compared to non-vocal areas (Belin et al., 2000). That is explained by the capacity of speech/non-speech sensory areas in the brain, whereby communication between conspecifics is emergent in both verbal (left superior temporal gyrus and bilateral posterior parietal) and non-verbal regions (right dorsolateral prefrontal cortex – DLPFC – and bilateral superior frontal gyrus) of the brain (Rothmayr et al., 2007; Shultz, Vouloumanos, & Pelphrey, 2012).
Acoustic features of both vocal (speech) and non-vocal (non-speech) stimuli are not processed the same way from the human brain (Joanisse & Gati, 2003). Voice (speech/non-speech)-selective areas are also located along the superior temporal sulci (STS) region of the right auditory cortex, indicating that neural projections in the STS are involved in the analysis of complex acoustic/non-acoustic features coming from vocal/non-vocal stimuli (Belin et al., 2000; Binder, Frost, Hammeke, Rao, & Cox, 1996). This is something supported by lesion studies, with patients who though could not recognise human voice, were able to identify the expressed content of a voice (Benzagmout, Chaoui, & Duffau, 2008). Non-speech, non-vocal and non-acoustic features of sound refer also to auditory and non-auditory stimuli entering the same areas found in temporal lobes – as explained above – both for those with sound – or hard hearing, as well as for those with non-hearing capacity at all (Traxler, 2012).
Findings that support STS bilateral activation for human vocal sounds show that such voice-selectivity is more evident when context-specific voices are heard, whereas the opposite is true for non-speech, non-vocal and non-acoustic features of sound (Patterson & Johnsrude, 2008). Speech processing refers to context-specificity and can be observed across several neural loci in the STS (Uppenkamp, Johnsrude, Patterson, Norris, & Marslen-Wilson, 2006), though little is known about its co-functional character to voice processing areas, when non-vocal stimuli are involved, such as pitch discrimination and pitch matching abilities in terms of amplitude-modulated stimuli of white noisev (Binder et al., 1999; Moore, Estis, Gordon-Hickey, & Watts, 2008; Steinschneider, 2012; Zatorre, Evans, Meyer, & Gjedde, 1992). An explanation could be that, speech processing relates to the production of articulated sounds, which can be understood in terms of linguistic and voice content (Bonte, Valente, & Formisano, 2009). Linguistic content is mainly located in the left (Morillon et al., 2010), whilst voice-content in the right hemisphere (Grossmann, Oberecker, Koch, & Friederici, 2010).
Human vocal sounds correspond to voice-selective areas in the auditory cortex, however, what about auditory stimuli that look similar to human voice, such as non-sense sounds or sounds associated to verbal communication, i.e., incomplete words or letters missing from words? Would they demonstrate the same neural activation? According to relevant research (Bélizaire, Fillion-Bilodeau, Chartrand, Bertrand-Gauvin, & Belin, 2007), the answer is that natural human sounds elicit cortical reactions at the STS, whereas voice-like stimuli reduce such reactions. The understanding of this finding is that voice-selective regions are contrasted to stimuli of human voice resemblance.
The literature on voice-selectivity apart from exploring human voice areas, explores also possible multimodal integration between auditory and visual systems (Campanella & Belin, 2007). Such integration, though it takes into account that auditory and visual cues are processed differently, it brings together voice and face selectivity associated with the speaker’s identity (Ward, 2010). That does not mean that auditory and visual parts are cortically related, but that the sensory information processed can simultaneously activate both cortices, if the person is familiar to the listener (Ethofer, Anders, Wiethoff, et al., 2006). Voice-selective regions in the auditory cortex might be seen as parallel to face-selective areas in the visual cortex, such as remembering one's voice by seeing one's face or remembering one's name by the way one is walking or sitting (Kanwisher, McDermott, & Chun, 1997). In this way, auditory and visual sensory systems can be functionally understood as being commonly designed for, so that to both react on human vocalisations and face recognition stimuli (Sweller, 2004).
Through functional magnetic resonance imaging (fMRI), cognitive neuroscience can identify brain regions related to the recruitment of voice and non-voice processing of sound (Vouloumanos, Kiehl, Werker, & Liddle, 2001). Voice-sensitive areas in the brain provide the cortical tools for the comprehension of auditory information (von Kriegstein, Eger, Kleinschmidt, & Giraud, 2003). Voice perception plays a significant role in identifying an individual speaking and the emotions one’s voice is carrying. Not much is known about its neural precursors (Belin et al., 2004; Imaizumi et al., 1997). By obtaining a fuller neural picture of the voice areas, human auditory cortex can be better understood in terms of connectivity with other brain parts (Belin et al., 2000).
The present report will be a partial replication of the Belin et al.’s (2000) study. Theoretically, this study, follows a study by Varvatsoulias (2013) which presents and discusses the neuroscientific background on fMRI and its importance in the scanning of neuronal activation. This study will investigate voice-selective regions in the human auditory cortex that mainly react to human vocal sounds. Belin et al.’s (2000) study is a seminal paper, for they were the first to point out that:
-
Superior temporal sulci areas in the right hemisphere, such as the anterior section of the temporal part – crucial for speaker’s identity – and, the central section of the anterior extension of Heschl’s gyrus (HG), and the posterior section of Heschl’s gyrusvi, show greater reactivity to human vocal sounds.
-
STS voice-selective response does not necessarily depend on speech vocal stimuli
-
Voice-selective areas can also respond to sounds of non-human origin
-
Voice-sensitive areas can be selectively recruited by a combination of high and low voice-featured frequency
-
By voice-responsiveness is not meant that voices are specifically elicited by voice-selective areas in the brain
-
Decreased neural activity in the auditory cortex can be a result of participants’ behavioural changes during performance on voice-perception tasks
-
Voice-selective regions may be regarded as analogous to face recognition processing
Rationale [TOP]
Voice-selective areas are differently activated from non-voice. The neural activation differs also among those areas in that it accounts for specialised and non-specialised processing of auditory information (Whalen et al., 2006).
Method [TOP]
Participants [TOP]
A healthy 24 years old male participant, native Greek and fluent English speakerviii.
Design [TOP]
1X3 repeated measures, event-related fMRI, ANOVA design; IVs: silence, voice, non-voice; DV: brain activity. Two conditions will be contrasted: sound (voice + non-voice) vs. silence and voice vs. non-voice.
Stimuli [TOP]
Auditory stimuli of sounds were presented at a sound-pressure level of 88-90dB. Stimuli were composed of sounds from a variety of sources in sixteen blocks of similar overall energy (RMS) by the use of Mitsyn (WLH) and CoolEdit Pro. Sounds were played for both ‘voice’ and ‘non-voice’ category with a rest period in-between. Sounds for the ‘voice’ category were human vocalisations, not essentially of speech, such as coughs, random utterances, nonsense words, or singing, whereas for the ‘non-voice’ were environmental sounds from nature, animals, or technology.
Procedure [TOP]
The participant was asked to close his eyes and listen to the presentation of various sounds. In both ‘voice’ and ‘non-voice’ categories sixteen blocks of sounds were delivered at onset times of ‘15 45 105 135 165 195 255 285’ and ‘30, 60, 90, 120, 180, 210, 240, 270’ seconds respectively. In the ‘voice’ category the subject passively listened to vocal sounds – speech or non-speech – coming from talkers of different age and gender; in the ‘non-voice’ category energy-matched non-vocal sounds were presented to the participant.
fMRI Recording Parameters [TOP]
A 3-T MRI Siemens trio scanner with a head coil of eight-channel array was employed. Standard gradient echo provided functional images of the whole brain via an echoplanar sequence of TR 3000ms, TE 33ms, 39 slices, 3x3x3 mm voxel size, 64x64 matrix, and a 90 degrees flip angle. Every experimental sequence was axially oriented, so pictures to be obtained successively. A 3-D whole brain T1-weighted anatomical mapping was obtained in a 1x1x1mm high resolution with a sequence of TR 1900ms, TE 5.57ms, and 11degrees flip angle.
Pre-Processing [TOP]
Re-alignment of functional images was carried out, so participant’s motion effects to be eliminated. Re-alignment was normalised according to the Montreal Neurological Institute (MNI) standard space, whereas it was also smoothed by the use of a 4MM Gaussain kernel. The image of the participant’s brain was normalised with a T1-weighted high-resolution, according to the identical MNI space, so results to be efficiently presented.
Statistical Methods for Data Analysis [TOP]
The general linear model (GLM) was employed for the analysis of data. Regressors’ inputs were generated to the model by following the convolution of the on-off block cycle. This corresponded to the Voice/Non-Voice presentation period of stimuli with reference to hemodynamic function, so dispersion and delay of the events following stimuli to be measured in regard to neural responses. Contrasts been used were the ‘Voice + Non-Voice overall effect vs. Silence’ (F Contrast), and regions responding to the stimulation of ‘Voice over Non-Voice’ (t Contrast). Significant activation of voxels at a p < .05 statistical threshold was assumed, being family-wise error (FWE) corrected for, again at a p < .05 threshold.
Results [TOP]
The critical value F = 16.4 (p < .05) shows significantly higher activation, bilaterally in the superior temporal gyri (STG, with x = 58, y = -18, and z = 12 coordinates), in the sound (voice + non-voice) category compared to silence. The critical t-value (t > 5.16, p < .05) shows significantly greater activation, bilaterally in the STS (with x = 76, y = 50, and z = 16 coordinates), for human vocal sounds compared to non-human (see Figure 1 and Figure 2).
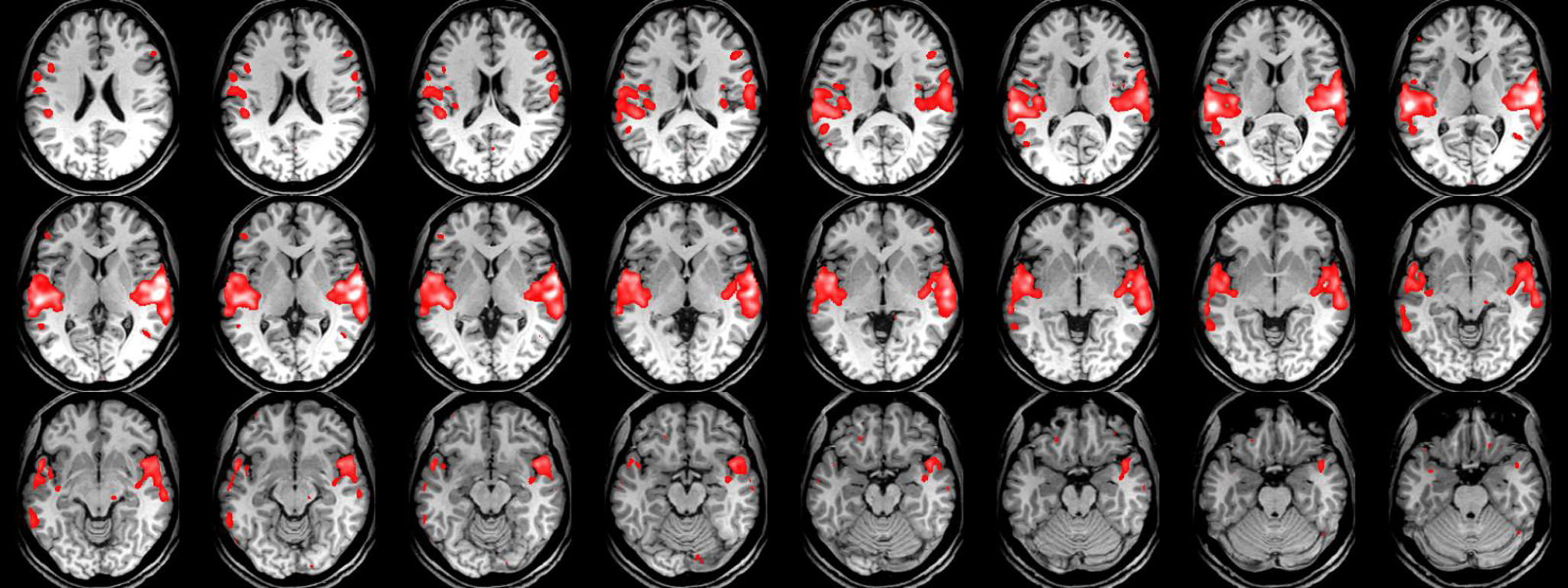
Figure 1
Images correspond to brain areas scanned by fMRI. Sound areas in the superior temporal gyrus area are slightly more demonstrated in the right cerebrum compared to silence ones which are mainly located in the superior temporal gyrus area of the left cerebrum.
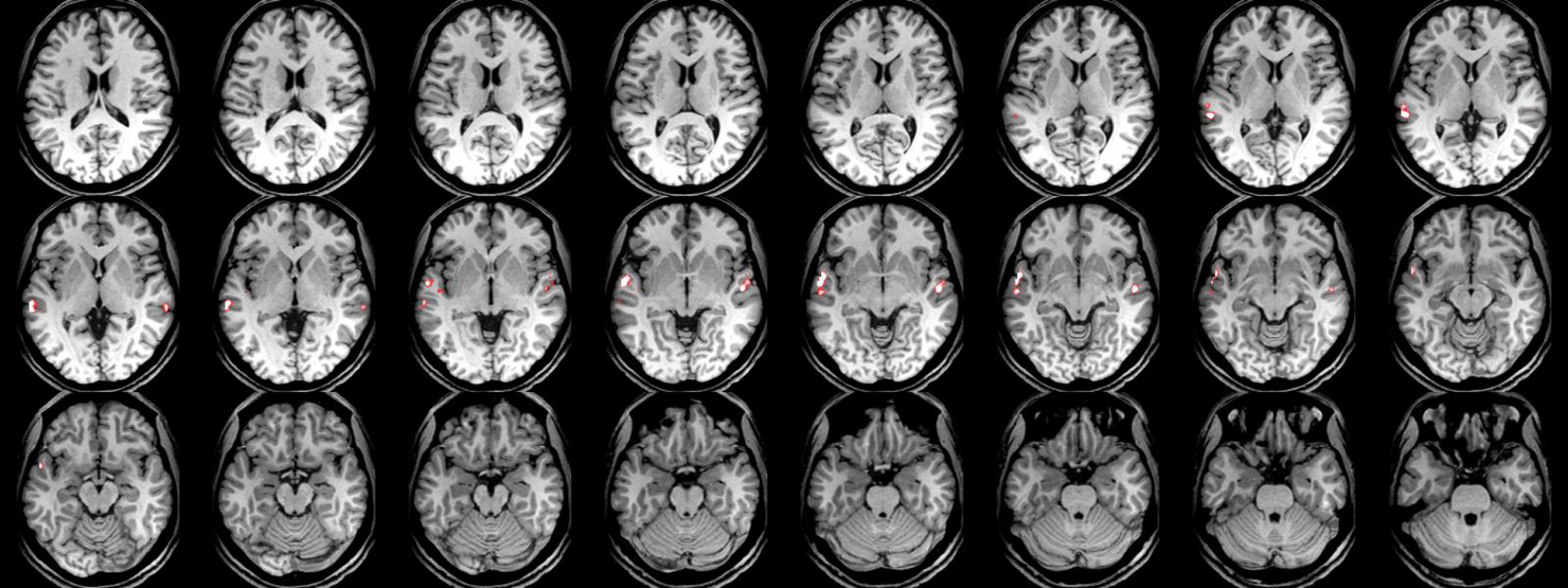
Discussion [TOP]
Having explained the reasons in footnote viii why there has been conducted a single participant study, the hypothesis is supported in the light of the results obtained. Auditory cortex is specifically activated by human vocal sounds compared to non-human. Voice-sensitive areas in the brain – speech or non-speech – are bilaterally activated in the STS, whereas sound regions bilaterally in the STG. Auditory areas in the brain demonstrate greater sound selectivity than voice/non-voice.
This partial replication agrees to the findings argued by the paper (Belin et al., 2000) that the superior temporal sulci are mainly voice- and not non-voice selective. Findings of this fMRI study portray areas in the auditory cortex with higher neural activation to sound compared to voice-sensitive areas. Findings show that the brain consists of specific auditory regions which are voice-selective. Findings exhibit that voice-selectivity is not only sensitive to sounds of human origin. Findings conclude that voice-selective areas respond to human and not non-human voice.
According to the findings outlined, human vocalisations activate the left hemisphere compared to alternate sound categories. This confirms that voice sounds elicit neural arrays mainly of human-voice responsiveness (Charest et al., 2009). In listening to sounds, there is more cortical tissue activated in the right hemisphere than in the left, as well as better neural response compared to silence. Neural responsiveness to sounds can also be subject to the intensity of pitch during which sounds are heard (Palmer & Summerfield, 2002).
In this single participant study, voice-sensitive areas in the STS were shown to be mainly located in the left hemisphere, and not in the right, as the paper (Belin et al., 2000) has argued. That, though does not render the paper's (Belin et al., 2000) findings ineffective, for individual differences can also be observed, it does however offer the hypothesis of little laterality for vocal stimuli in the brain and in particular to the auditory areas the fMRI scan has shown that during the process they become activated, i.e. in the STS area in the left cerebrum. Such hypothesis may offer continuation to the debate between hemispheric asymmetry in vocal processing and speech or linguistic processing, with or without the involvement of non-verbal affect burstsix, during the accomplishment of auditory information (Grossmann et al., 2010; Scherer, 1995). In line with what has been argued, as to the hypothesis stated above, mismatch negativity measurements in studies of event-related potentials (ERPs) seem to be in favour of such hypothesis. That is to say that in auditory perception, what is of crucial role is the presence or not of attention so that the linguistic experience, when obtained, to determine whether responses heard relate to speech or non-speech sounds (Näätänen, Paavilainen, Rinne, & Alho, 2007). By that it is meant that what is retained in the auditory sensory memory, and therefore forms part of auditory perception, is the cognitive comprehension of frequent – standard – and infrequent – deviant – sounds in terms of mismatch negativity (MMN) measurements so that auditory areas to be further studied (Näätänen, 1992)x. Moreover, and in reference to the above hypothesis, the rationale behind MMN is that such studies provide a clearer understanding about the ability of the brain to discern stimuli instead behaviours, with the former to be the outcome of factors related to attention issues and/or motivation, and the latter, the effect of actions in the here and now (Bishop & Hardiman, 2010).
On the other hand, the fact that the study was conducted with only one participant, cannot prove justice to a representative sample. If more participants took part in the study, the degree of same areas activation could vary, suggesting individual differences in the neural response to auditory information (Buchweitz, Mason, Tomitch, & Just, 2009). The participant was male, implying that gender differences in auditory information processing could also be suggested as an important element of discussion to neural activation, if there were to be recruited female participants as well (Brown, 1999).
Also, the participant was not a native English speaker, meaning that if subjects were both native and foreign speakers of English, neural performance could be studied in terms of bilingual proficiency as to the vocal stimuli presented (Fabbro, 2001). Participants, for instance, could read a text in English and then translate and read it in their own language in order for auditory cortex correspondence to be detected (Price, Green, & von Studnitz, 1999). Allocation also of an appropriate number of participants, males and females, native and non-native speakers, will generate more accurate findings and will eliminate confounding variables relevant to the limitations discussed. In such a study, there could also be investigated whether native vs. non-native language proficiency activates same or different cortical regions. In trying a study with more participants, what could further be tested would be auditory triggers in the form of verbal affect bursts associated with human voices, presented in one's native language as well as not. The purpose for such a study could be the research of affective elements of cognition in terms of emotional reasoning, and which parts of the brain are activated, when stimuli are heard in different languages (Belin et al., 2008). Such study could also include high and low-frequency words so that the effect of commonly/not so commonly words in neural responsiveness to be detected. Word frequency has been found to be associated with left inferior frontal activation (Ghee, Soon, & Hwee, 2005). In such a way, high and low word frequency would probably represent different neural arrays in terms of exposure consistency vs. inconsistency (Balota & Chumbley, 1985).
In view to such a study, therefore, what could also be researched as well would be whether the auditory cortex precipitates, or is precipitated by, the neural activation of visual cortex, if participants were to see the words when these were uttered to them. A parallel study to that could be looking at familiar faces on a computer and then verbally recalling their names, and vice versa. What could be measured would be the time needed to recall a name versus face, and the neural activation of brain regions during both conditions. In such a study, findings could probably refer to greater or lower neuronal response between voice and face-selective areas. Also, as to such a study, faces of high versus low familiarity could probably extend neural activation mapping to other lobes of the brain too, such as the occipital lobes, whereby seeing a face could suggest increased or decreased activation in neural arrays; something that could also be the case as for words of high and low frequency (Hintzman, 1988). In this way, the study of known vs. less known faces and high vs. low-frequency words could therefore question the effect of commonly used words vs. not, in neural receptivity. Word frequency has been found to be associated with left inferior frontal activation (Ghee et al., 2005). In such a way, words of high and low frequency may probably represent different neural arrays when examined in respect to exposure consistency vs. inconsistency (Balota & Chumbley, 1985).
It has also been argued that neural recruitment of information depends on all kinds of sounds whether voice/non-voice, or speech/non-speech (Patterson & Johnsrude, 2008). To such an extent, should a study be conducted could investigate species-specificity areas in the brain by looking at voice/non-voice and speech/non-speech neural responsiveness. What could be examined in that sense would be issues of neural activation between spoken and non-spoken information (Jaramillo et al., 2001), as well as voice and speech-related sounds associated with literal and abstract linguistic content. What could be explored would be the corresponding cortical activation of species-specificity areas to literal and abstract linguistic content for both voice and speech vocalisations of human origin (Fecteau, Armony, Joanette, & Belin, 2004).
Furthermore, the investigation whether the auditory cortex elicits or elicited by visual cortex activation could be another important chapter researching co-functionality issues between sensory regions (Wheeler, Petersen, & Buckner, 2000). Participants could look at familiar faces, and then asked to recall their names. What could be measured would be the elapsed time from the onset of each face to the recollection of name, and the neural activation of brain regions during both conditions. Findings-to-be may predict greater or lower neural correspondence between voice and face-selective modalities (Campbell, 2008).
Last, but not least, the neural activation to voice-selectivity has been an issue of discussion in evolutionary psychology as well. This is because humans are capable in distinguishing environmental sounds differently to voices of conspecifics. We have observed in this study that areas of sound are more distinctly illuminated compared to areas of human vocal sounds. That may be a reason of evolutionary origin, since human life depends on surrounding sounds, which are many, compared to sounds of human origin, which are relatively less. The latter refers to context-specific adaptive problems, whereas the former to universal acoustic features affecting everyone (Westman & Walters, 1981).
Humans mainly communicate with each other by the use of species-specific vocalisations, whereas communication with the environment involves more complex interplay of sounds (Gygi, Kidd, & Watson, 2007). Voice-selective areas in the brain can be evolutionarily explained in terms of sociality-adaptive problems that had to be resolved in order for ancestral communities to be able to survive (Locke, 2008). Human voice was a costly signal, and a prominent indicator of communication and cooperation in ancestral environments (Fisek & Ofshe, 1970). Adaptive problems, such as group formation, in-group alliances, out-group conflict, competition strategies, mating preferences, social exchange practices, and cheater detection, were an everyday struggle between conspecifics that had to be regulated (Barrett, Dunbar, & Lycett, 2002).
Day-to-day adaptations and survival needs in given milieus were however costlier than those of personal and social focus (Corning, 2000). Adaptive challenges elicited greater importance to survival needs long before humans established interrelationships (Cornwell et al., 2007), something that is argued to be the reason for sound-sensitive areas in the brain (Hester, 2005). In light therefore to evolutionary findings, should a hypothesis be suggested could question adaptations in view to societal needs sound-selective regions have been selected for to demonstrate higher neuronal activation compared to voice-selective regions.
Conclusions [TOP]
This fMRI report was a single-participant study due to time restrictions to collect data as to the availability of the scanner, as well as that the participant was bilingual, compared to the study that was partially replicated (Belin et al., 2000), which included only an English-speaking sample. Though from a single-participant study cannot be justified findings referring to a particular population of a sample, this study did actually support the hypothesis that human voice elicits greater activation than non-human voice. The present study further supports the hypothesis for a continuation of the debate between hemispheric asymmetry in vocal processing, and speech or linguistic processing, with or without the involvement of non-verbal affect bursts during the accomplishment of auditory information. In that, little laterality for vocal stimuli in the brain could increase the discussion towards understanding the issue of hemispheric asymmetry as an ongoing neural process for the accommodation of auditory information. Human vocal sounds are more significantly activated compared to non-human, which implies that human voice is context-specific, whereas non-human voice is not. Sound areas in the brain are also more considerably activated compared to silence, in that they refer to a large amount of vocal vs. non-vocal sounds, in that they can be triggered by a richer array of environmental stimuli.
Also, voice-selective areas were found to neural loci bilateral to superior temporal sulci, whilst sound-selective areas were bilaterally activated to superior temporal gyri. In a future replication of this study more participants from both genders should take part; issues of bilingual significance as to neural activation and performance could also be included in the discussion; whereas also, aspects of neural activation and species-specificity of voice/non-voice and speech/non-speech could be looked as well. Last, but not least a further discussion in regards to the evolutionary importance of neuronal activation of sound-receptive regions compared to voice could be investigated, so that adaptive explanations to be elaborated in the discussion.
